Hierarchical Forecasting Settings
- Task Settings
- Diagnostics Settings
- Model Generation Settings
- Model Selection Settings
- Reconciliation Settings
- Output Tables
You can change the following settings in the Options pane of the pipeline. For more information, see Options Pane.
Task Settings
- Set the forecast task
-
Specify the task to run for this modeling node. These tasks must be run sequentially. For example, the Diagnose task can be run independently, but the Fit task requires that you run the Diagnose task first.
Choose from one of the following tasks:
- Diagnose : performs model selection, estimates parameters of the selected model, and produces forecasts. This is the default.
- Fit : estimates parameters for the models that you select and then forecasts. No model selection is performed. You must run the Diagnose task successfully before running the Fit task.
- Forecast : forecasts using model parameter estimates. You must run the Diagnose task successfully before running the Forecast task. After the Diagnose task has been run, if any settings are changed, the Diagnose task must be run again before running the Forecast task.
- Select : performs model selection from the models that you select, estimates parameters of the selected model, and produces forecasts. You must run the Diagnose task successfully before running the Select task.
- Update : estimates parameters from the models that you select and then forecasts. No model selection is performed. Update differs from Fit in that the estimated parameters are used as starting values in the estimation. You must run the Diagnose task successfully before running the Update task. After the Diagnose task has been run, if any settings are changed, the Diagnose task must be run again before running the Update task.
Diagnostics Settings
Changes to these settings require that you rerun the pipeline.
- Intermittency test
-
Turn this setting on to perform an intermittency test and use the IDM model for intermittent series
- Sensitivity level for intermittency test
-
Specify an integer greater than one. This setting is used to determine whether a time seriesan aggregation of transactional data into specified time intervals and sorted according to unique combinations of the default attributes (BY variables) is intermittent. If the demand interval is equal to or greater than this number, then the series is assumed to be intermittent.
- Seasonality test
-
Turn this setting on to perform seasonalitya regular change in time series data values that occurs at the same point in each time cycle. testing for ESM models for the time series
- Sensitivity level for seasonality test
-
Specify the significance probability value to use in testing whether seasonality is present in the time series. The value must be between 0 and 1. A smaller value means that a stronger evidence of a seasonal pattern in the data is required before seasonal models are used to forecasta numerical prediction of a future value for a specified time period for each unique combination of BY variable values the time series.
Note: If the seasonality test setting is turned off, a default sensitivity of 0.05 is used to determine seasonality for the ESM model. If you want to exclude seasonal ESM models, set the ESM model method to BESTN.
- Diagnose independent variable
-
Select from the following options:
- Transform: specifies that a transformation is applied to the time series
- Trend: specifies that trend analysis is performed on the time series based on the setting for minimum nonmissing values. Incorporation of a trend is checked only for smoothing, UCM, and ARIMA models. For the smoothing case, only simple smoothing is a non-trend model. For UCM, the absence of a slope component qualifies it as a non-trend model. For ARIMA, there must be no differencing of the dependent variable for the time series forecasting engine to consider it as a non-trend model.
- Both: specifies that transformation and trend analysis is performed for the time series
- None: specifies that no transformation or trend analysis is performed for the time series
- Transformation
-
- Dependent variable transformation
-
specify the type of functional transformation:
- Auto: Selects between logarithmic or no transformation as determined by the model selection criteria
- Box-Cox: Box-Cox transformation
- Log: Logarithmic transformation
- Logistic: Logistic transformation
- None: No transformations are processed on the time series
- Square root: Square-root transformation
- Box-Cox parameter
-
Specify a number for the exponent, lambda (λ), which varies from -5 to 5, exclusive. This setting is enabled only if Functional transformation (dependent) is set to
Box-Cox. - Forecast
-
Specify the forecast method when functional transformation is enabled. Forecasts can be based on the mean or median. By default the mean value is provided. This setting is disabled if Dependent variable transformation is set to
None.
- Minimum number of observations required for a non-mean model
-
Specify a minimum value that a time series must meet to be fit using the models in the selection list. Time series that do not meet this minimum value are forecast as the mean of the observations in the series. This value must be greater than or equal to one. The default value is 2.
- Minimum number of observations required for a trend model
-
Specify that a trend model is not fitted to any series with fewer nonmissing observations than the value specified. The value must be an integer that is greater than or equal to 1. The default value is 2. Trend models are not included for any series with fewer nonmissing observations than this value.
Incorporation of a trend is checked only for smoothing, UCM, and ARIMA models. For the smoothing case, only simple smoothing is not a trend model. For UCM, the absence of a slope component qualifies it as not a trend model. For ARIMA, there must be no differencing of the dependent variable for it to be considered as not a trend model.
- Minimum number of seasons required for a seasonal model
-
Seasonal models are not included for any series with fewer nonmissing observations than this value, multiplied by the seasonal length. Specify an integer greater than or equal to one.
Model Generation Settings
Changes to these settings require that you rerun the pipeline.
For best results, make sure at least two of these models are selected. If none of the models are selected, an ESM model (ESM BEST) is used for all time series.
- Include ARIMAX models
-
Turn this setting on to include an ARIMAX model for diagnosis. With this setting on, you can set the control options for ARIMAX model parameter refinement. You can set the order in which eventsan incident that disrupts the normal flow of any process that generates the time series. Examples of events are holidays, retail promotions, and natural disasters., inputs, or ARIMA components are included in the models. You can also set a significance level between 0 and 1.
The following settings are enabled when ARIMAX is turned on.
- Identification order for input variable and event coefficients
-
Select one of the following options for the order in which input or ARIMA components are included in the model.
- Create two models, each of which uses a different identification method for model inclusion
- Identify coefficients for ARMA components before input variables and events
- Identify coefficients for input variables and events before ARMA components
- Refinement
-
Specify ARIMA parameter refinement options. These options enable the refinement of insignificant parameters of the final model, identification of the factors to refine, and identification of the order of factors.
Factor option: Select from the available options to determine the order for diagnosing model components. For example, if you select ARMA:INPUT, ARMA coefficients are tested before input variable coefficients.
Significance level: Enter a number between 0 and 1 that specifies the cutoff value for refining all insignificant parameters
- Outlier Detection Settings
-
Use the following for detecting outliers.
- Specify
the criterion for outlier detection —
Select Yes to include detected outliers in a model if the model is successfully diagnosed.
Select Maybe to include detected outliers in a model if the model is successfully diagnosed and has a smaller criterion than the model without outliers.
Select No to ensure that no outlier detection is performed.
- Specify the maximum number of outliers — Provide a nonnegative integer that specifies the maximum number of outliers to include in a model. The actual number of outliers is the minimum number between this value and Specify the maximum percentage of outliers.
- Specify the maximum percentage of outliers — Provide a number between 0 and 100 that specifies the maximum number of outliers to include in a model as a percentage of the length of the dependent time series. The actual number of outliers is the minimum number between this value and Specify the maximum number of outliers.
- Significance level — Provide a value between 0 and 1 that specifies the cutoff value for outlier detection.
- Specify
the criterion for outlier detection —
- Include ESM models
-
With this setting on, specify how the best ESM model candidate is chosen.
- BEST
-
uses seasonal properties of the data to choose between the BESTN and BESTS methods. If data consists of a single seasonal cycle, the BESTN method is used. Otherwise, a seasonal test is performed, and if the data is seasonal, then the BESTS method is used. If the seasonal test does not indicate seasonality, then the BESTN method is used. The significance level of the seasonality test is 0.05.
- BESTS
-
requests the best candidate seasonal smoothing model among the seasonal, additive Winters, or multiplicative Winters methods.
- BESTN
-
requests the best candidate nonseasonal smoothing model among the simple, linear, or damped-trend methods.
- Include UCM models
-
Turn this setting on to include an UCM model for diagnosis.
- Include external models
-
Turn this setting on to include an external model to use for diagnosis.
Models from an external data source - Enter the CAS library and table name for the external model, for example:
casuser.externalmodel.Note:- The external model name cannot exceed 32 bytes.
- If the external model uses a dummy data set, any independent variables declared in the dummy data set must use the same names as the independent variables in the project time series. Otherwise, the external model is not used.
- If the external model cannot be found in memory or in the file system, a warning is issued and the node execution proceeds.
- Number of levels required to use the system-generated ESM models
- (starting from the lowest level)
-
Specify an integer ranging from 1 to the number of levels in the project hierarchythe order of the variables that you have assigned to the BY variables role. An example of a hierarchy is Region > Product Category > Product Line. . A bigger number means the higher level in the hierarchy. The default is 0.
For example, if the hierarchy is regionName
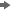 productLineproductName, then the valid
value could be one of the following:
productLineproductName, then the valid
value could be one of the following: - 0 — not applicable
- 1 — apply for productName
- 2 — apply for the productLine and the productName
- 3 — apply for the regionName, the productLine, and the productName
- Include combined models
-
Specify whether to combine the selected models other than the external ones
- Method for combination
-
Specify the method for determining the combination weights used in the weighted average of the candidate forecasts in the combination list. Choose from one of these options:
- Akaike weights using AICC values — computes the combination weights based on corrected AIC weights. By default, all AICC scored candidate forecasts are combined. Frequently, there is considerable disparity between the weights because of the exponential weighting scheme, so additional arguments are provided to affect the scaling and to cull low-scoring candidates from consideration for computational efficiency.
- Average — computes the simple average of the forecasts selected for combination
- Equality constrained least squares — computes the combination weights based on a constrained least squares problem to minimize the L2 norm of the combined forecast residuals subject to the constraint that the weights sum to 1.
- Equality constrained, non-negative least squares — computes the combination weights based on a constrained least squares problem to minimize the L2 norm of the combined forecast residuals subject to the constraints that the weights sum to 1 and be nonnegative.
- Least absolute deviations — computes the combination weights that result from the ordinary least squares problem to minimize the L2 norm of the combined forecast residuals.
- Non-negative
least squares — is equivalent to
Equality constrained, non-negative least squaresexcept that the resulting combination weights are not constrained to summing up to 1. - Ordinary least squares — computes the combination weights that result from the ordinary least squares problem to minimize the L2 norm of the combined forecast residuals.
- Ranked weighting — assigns weights by using the rank of the candidate forecasts when the combination is performed.
- Scaled RMSE weights — computes the combination weights based on the RMSE statistic of fita statistical value that is used to evaluate how well a forecasting model fits the historical series by comparing the actual data to the predicted values. for the forecast contributors. The weights are normalized to sum to 1.
- Statistic used for the encompassing test
-
specify the encompassing test type. The encompassing test attempts to eliminate from consideration forecasts that fail to add significant information to the final forecast. Select one of the following values.
- HLN — uses the Harvey-Leybourne-Newbold (HLN) test to estimate pairwise encompassing between candidate forecasts
- NONE — performs no encompassing tests
- OLS — uses an OLS-based regression test to estimate pairwise encompassing between candidate forecasts
- Encompassing test parameters
-
These fields are disabled if Statistic used for the encompassing test is set to None.
- Significance level for the encompass test — specifies the encompassing test significance level. The default value is 0.05.
- Rank criterion — specifies the forecast combination criterion (statistic of fit) to be used when ranking forecast candidates in the context of the model combination. For descriptions for each option, see Descriptions of Model Selection Criteria.
- Missing value interpretation
-
specifies a method for treating missing values in the forecast combination. In a given time slice across the combination ensemble, one or more combination contributors can have a missing value. This setting determines the treatment of those in the final combination for such time indices.
- Rescale — rescales the combination weights for the nonmissing contributors at each time index to sum to 1.
- Missing — generates a missing combined forecast at each time index with one or more missing contributors.
- Method to compute the prediction error variance
-
specifies the method for computing the prediction error variance series. This series is used to compute the prediction standard error, which in turn is used to compute confidence bands on the combined forecast. Select from the following options.
- DIAG — computes the prediction error variance by assuming the forecast errors at time t are uncorrelated so that the simple
diagonal form of
 t is used. This is the default
method for computing prediction error variance.
t is used. This is the default
method for computing prediction error variance. - ESTCORR —
computes the prediction error variance by using estimates of
 , the sample cross-correlation between
, the sample cross-correlation between  and
and  over the time span
over the time span  , where t denotes the last
time index of the actual series
, where t denotes the last
time index of the actual series  . Of course, this option implies that the error series
and are assumed to be jointly stationary.
. Of course, this option implies that the error series
and are assumed to be jointly stationary.
- DIAG — computes the prediction error variance by assuming the forecast errors at time t are uncorrelated so that the simple
diagonal form of
- Maximum allowed percentage of missing in-sample data:
-
specifies a threshold for the percentage of missing forecast values in the combination estimation region that is used to exclude a candidate forecast from consideration in the final combination. By default, no missing percentage test is performed on candidate forecasts. If specified, the admissible range is 1 to 100.
- Maximum allowed percentage of missing forecast values in the horizon
-
specifies a threshold for the percentage of missing forecast values in the combination horizonthe number of intervals into the future, beyond a base date, for which analyses and predictions are made. used to exclude a candidate forecast from consideration in the final combination. By default, no horizon missing percentage test is performed on candidate forecasts. If specified, the admissible range is 1 to 100.
Model Selection Settings
Changes to these settings require that you rerun the pipeline.
- Number of data points used in the holdout sample
-
Enter a positive integer to be used as the size of the holdout samplethe number of periods of the most recent data that should be excluded from the parameter estimation. The holdout sample can be used to evaluate the forecasting performance of a candidate model.. The actual holdout sample is the minimum between this value and the Percentage of data points used in the holdout sample . The default value is zero, which means no holdout sample is used.
- Percentage of data points used in the holdout sample
-
Enter a value between 0 and 100 to specify the percentage of the sample that is used for the holdout sample. The actual holdout sample is the minimum between this value and the Number of data points used in the holdout sample . This option is displayed only if Number of data points used in the holdout sample is greater than zero.
- Model selection criterion
-
Choose the statistics of fit to use for selecting the best model in this modeling node. For descriptions for each option, see Descriptions of Model Selection Criteria.
Reconciliation Settings
Setting the reconciliation level overrides the default setting selected when assigning the BY variable roles for the project on the Data tab. For more information, see Assigning the Default Attributes.
- Specify the reconciliation level
-
The reconciliation level is specified for this node by selecting a BY variable from the hierarchy. Consider the order of the default attributes (BY variables) defined on the Data tab. Select a variable to determine the type of reconciliation methodthe method that specifies the level in the hierarchy where the process of reconciliation starts. The following reconciliation methods are available: bottom-up method, middle-out method, and top-down method. .
- Select Top to perform top-down reconciliation.
- Select the variable at the bottom of the hierarchy
to use bottom-up reconciliation. For example, if the hierarchy consists of two default
variables,
Locationat the top andNameat the bottom, selectNameto perform bottom-up reconciliation. - You can select a variable in the middle level of
the hierarchy to use middle-out reconciliation. For example, if the hierarchy consists
of three
default variables in the order of
High,Medium, andLow(withHighat the top), specifyMediumto generate forecasts for that level and then reconcile forecasts for the upper and lower levels in the hierarchy.
By default, the reconciliation level set on the Data tab for the BY variables is used.
For a description of top-down, middle-out, and bottom-up reconciliation methods, see Understanding Hierarchy Reconciliation.
- Disaggregation method during top-down disaggregation
-
specifies the type of disaggregation methoda method that specifies how the forecasts in the lower level of the hierarchy are reconciled when the reconciliation method is top-down or middle-out. The disaggregation method can reconcile the forecasts in either of the following ways: (1) by using the proportion that each lower-level forecast contributes to the higher-level forecast; or (2) by splitting equally the difference between the higher-level forecast and the lower-level forecasts. and type of loss function for top-down reconciliation. Select one of the following methods for top-down disaggregation:
- Difference — bases the loss function on the root mean square error (RMSE). This results in adjustments that are the (possibly weighted) mean difference of the aggregated child nodes and the parent node.
- Proportions — uses a loss function that results in reconciled forecasts that are the (possibly weighted) proportional disaggregation of the parent node.
Output Tables
The following tables are automatically generated when running this modeling node. The tables can be saved to another caslib by using the Save Data Node.
- Statistics of Fit (OUTSTAT)
- Descriptive Statistics (OUTSUM)
- User-Defined and Derived Attributes (MERGED_ATTRIBUTES)
- Model Attributes (OUTMODELINFO)
- Model Selection Statistics (OUTSELECT)
- Log Messages (OUTLOG)
- Forecasted Values (OUTFOR)
The following optional tables can be selected for generation. Select any tables that you want generated when this node is run. After the node is run, the tables can be saved using the Save Data Node.